概述
Channel用于在字节缓冲区和位于通道另一侧的实体(通常是一个文件或套接字)之间有效地传输数据。多数情况下,Channel与操作系统的文件描述符(File Descriptor)和文件句柄(File Handle)有着一对一的关系。通道是一种途径,借助该途径,可以用最小的总开销来访问操作系统本身的I/O服务。缓冲区则是通道内部用来发送和接收数据的端点。下图中的箭头展示了channel在连接IO服务的时充当的角色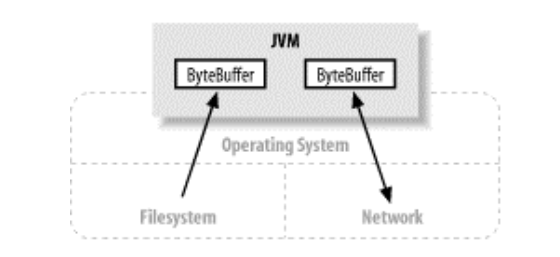
有两种类型的Channel:
文件通道,对应FileChannel类
套接字通道,对应SocketChannel、 ServerSocketChannel 和 DatagramChannel类
概念与原理
Scatter/Gather
Scatter/Gather是一个简单却强大的概念,也称为矢量IO,大多数现代操作系统都支持本地矢量IO。当我们在一个通道上请求一个Scatter或Gather操作时,该请求会被翻译为适当的本地调用来直接填充或抽取缓冲区
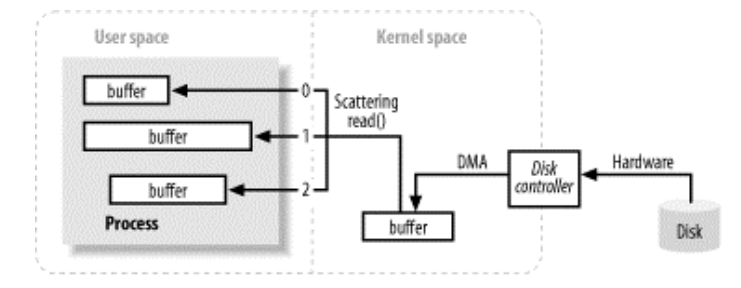
关于图中DMA,用户空间,内核空间等概念,可以参考Java NIO 学习之背景知识
如上图所示,进程只需一个系统调用,就能把一连串缓冲区地址传递给操作系统。然后,内核就可以顺序填充或排干多个缓冲区,读的时候就把数据发散到多个用户空间缓冲区,写的时候再从多个缓冲区把数据汇聚起来。这样,用户进程就不必多次执行系统调用(那样做可能代价不菲),内核也可以优化数据的处理过程,因为它已掌握待传输数据的全部信息。如果系统配有多个CPU,甚至可以同时填充或排干多个缓冲区。
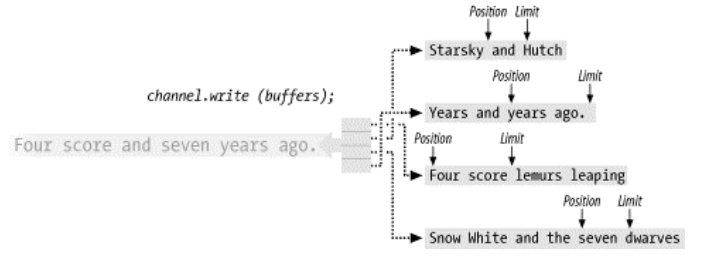
在NIO中,Scatter/Gatter的相关API是channel的数组形式的read和write操作,如read(ByteBuffer[] dsts)和write(ByteBuffer[] srcs)等,下面分别用图示解释这两种操作的数据移动的结果:下图描述了一个gather写操作。数据从缓冲区阵列引用的每个缓冲区中gather并被组合成沿着通道发送的字节流。
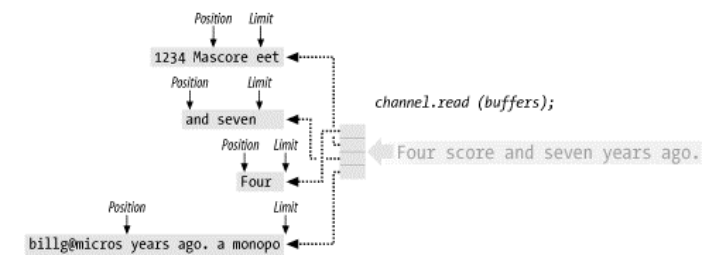
描述了一个 scatter 读操作。从通道传输来的数据被scatter到所列缓冲区,依次填充每个缓冲区(从缓冲区的position处开始到limit处结束)。这里显示的position和limit值是读操作开始之前的。
文件通道
每个FileChannel对象都同一个文件描述符有一对一的关系,在FileChannel出现之前,底层的文件操作都是通过RandomAccessFile类的方法来实现的。FileChannel模拟同样的I/O服务,因此它们的API自然也是很相似的。为了便于比较,下图列出了FileChannel,RandomAccessFile和POSIX I/O系统调用在方法上的对应关系

同底层的文件描述符一样,每个FileChannel都有一个叫position的概念。这个position值决定文件中哪一处的数据接下来将被读或者写。position是从底层的文件描述符获得的,该position同时被作为通道引用获取来源的文件对象共享,这也就意味着一个对象对该position的更新可以被另一个对象看到。
类似于缓冲区的get()和put()方法,当字节被read()或write()方法传输时,文件position会自动更新。如果position达到了文件大小的值(文件大小的值可以通过size()方法返回),read()方法会返回-1。可是,不同于缓冲区的是,如果使用write()方法时position前进到超过文件大小的值,该文件会扩展以容纳新写入的字节。
获取通道的几种方法
1.调用支持通道的类的getChannel()方法
本地IO:FileInputStream/FileOutputStream、RandomAccessFile
网络IO:Socket、ServerSocket 、DatagramSocket
Socket的相关类调用getChannel()不会创建新的通道,只会返回与之对应的channel。意思是,如果先实例化来创建Socket,然后调用getCahnnel则会返回null,而先创建SocketChannel,调用其socket()方法得到socket后,在此socket上调用getChannel才会返回与之对应的channel
2.调用各个通道的静态方法open()
3.调用Files工具类的newByteChannel()
4.调用Channels.newChannel(InputStream in)或Channels.newChannel(OutputStream out)
文件锁定
在不同的操作系统上,甚至在同一个操作系统的不同文件系统上,文件锁定的语义都会有所差异。我们应该总是按照劝告锁的假定来管理文件锁,因为这是最安全的。文件锁类型的区别见Java NIO 学习之背景知识
如果一个线程在某个文件上获得了一个独占锁,然后第二个线程利用一个单独打开的通道来请求该文件的独占锁,那么第二个线程的请求会被批准。但如果这两个线程运行在不同的 Java 虚拟机上,那么第二个线程会阻塞,因为锁最终是由操作系统或文件系统来判优的并且几乎总是在进程级而非线程级上判优。锁都是与一个文件关联的,而不是与单个的文件句柄或通道关联
FileLock推荐使用形式
管道Pipe
用于线程间通信。Pipe类定义了两个嵌套的通道类,这两个类是Pipe.SourceChannel(管道负责读的一端)和 Pipe.SinkChannel(管道负责写的一端),如下图所示
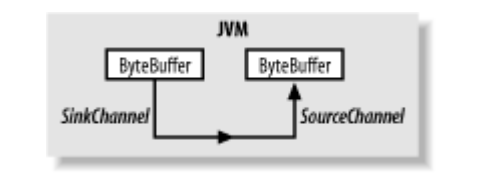
这两个通道实例是在Pipe对象创建的同时被创建的,可以通过在Pipe对象上分别调用source( )和sink( )方法来取回。管道可以被用来仅在同一个Java虚拟机内部传输数据。虽然有更加有效率的方式来在线程之间传输数据,但是使用管道的好处在于封装性。生产者线程和用户线程都能被写道通用的Channel API中。根据给定的通道类型,相同的代码可以被用来写数据到一个文件、socket或管道。选择器可以被用来检查管道上的数据可用性,如同在socket通道上使用那样地简单。这样就可以允许单个用户线程使用一个Selector来从多个通道有效地收集数据,并可任意结合网络连接或本地工作线程使用。因此,这些对于可伸缩性、冗余度以及可复用性来说无疑都是意义重大的。
Channel通用API
read(ByteBuffer dst)
从channel中读取数据到dst中
|
|
read(ByteBuffer[] dsts)
对dsts中的所有ByteBuffer执行gather操作
read(ByteBuffer[] dsts, int offset, int length)
对dsts中的部分ByteBuffer执行gather操作。offset参数是指哪个缓冲区将开始被使用,而不是指数据的 offset。length参数指示要使用的缓冲区数量。
write(ByteBuffer src)
将src中的数据写入到channel中
|
|
write(ByteBuffer[] srcs)
对srcs中的所有ByteBuffer执行scatter操作
使用
while (channel.write(bs) > 0){}来确保已经将srcs中所有buffer的有效数据都被写入channel
write(ByteBuffer[] srcs, int offset, int length)
对srcs中的部分ByteBuffer执行scatter操作。offset参数是指哪个缓冲区将开始被使用,而不是指数据的 offset。length参数指示要使用的缓冲区数量。
下面是实现通道之间复制数据的代码,代码中的两个循环条件是经常被使用的
|
|
文件通道独有API
position()
返回当前文件通道的position值
position(long newPosition)
将文件通道的position设置为指定值
read(ByteBuffer dst, long position)
在文件通道的position处开始读取
write(ByteBuffer src, long position)
在文件通道的position处开始写入
truncate(long size)
将文件截断至指定大小
force(boolean metaData)
告诉通道强制将全部待定的修改都应用到磁盘的文件上。布尔型参数metaData表示在方法返回值前,文件的元数据是否也要被同步更新到磁盘。
所有的现代文件系统都会缓存数据和延迟磁盘文件更新以提高性能。调用force()方法要求文件的所有待定修改立即同步到磁盘。如果文件位于一个本地文件系统,那么一旦方法返回,即可保证从通道被创建或上次调用 force()时起的对文件所做的全部修改已经被写入到磁盘。对于关键操作如事务处理来说,这一点是非常重要的,可以保证数据完整性和可靠的恢复。
lock(long position, long size, boolean shared)
指定文件内部锁定区域的开始position以及锁定区域的size。第三个参数 shared 表示想获取的锁是共享的还是独占的要获得一个共享锁,必须先以只读权限打开文件,而请求独占锁时则需要写权限。锁定区域的范围不一定要限制在文件的size值以内,锁可以扩展从而超出文件尾。因此,我们可以提前把待写入数据的区域锁定,我们也可以锁定一个不包含任何文件内容的区域,比如文件最后一个字节以外的区域。如果之后文件增长到达那块区域,那么文件锁就可以保护该区域的文件内容了。相反地,如果锁定了文件的某一块区域,然后文件增长超出了那块区域,那么新增加的文件内容将不会受到文件锁的保护
lock()
等价于fileChannel.lock (0L, Long.MAX_VALUE, false);,这是在整个文件上请求独占锁的便捷方法,锁定区域等于它能达到的最大范围
如果请求的锁定范围是有效的,那么lock()方法会阻塞,它必须等待前面的锁被释放
tryLock()与tryLock(long position, long size, boolean shared)
lock()方法的非阻塞形式,如果请求的锁不能立即获得则会返回null
map(MapMode mode, long position, long size)
在一个打开的文件和一个MappedByteBuffer之间建立一个虚拟内存映射。position和size参数的含义与lock()中的参数含义相同,但size不应超过文件大小,否则会造成文件空洞。mode参数指定文件映射的模式,使用FileChannel类的内部类MapMode静态字段指定,共有三种模式:READ_ONLY,READ_WRITE,PRIVATE。
MapMode.PRIVATE表示一个写时拷贝(copy-on-write)的映射。这意味着通过 put()方法所做的任何修改都会导致产生一个私有的数据拷贝并且该拷贝中的数据只有MappedByteBuffer实例可以看到。该过程不会对底层文件做任何修改,而且一旦缓冲区被施以垃圾收集动作,那些修改都会丢失。选择使用 MapMode.PRIVATE模式并不会导致得到的缓冲区看不到通过其他方式对文件所做的修改,对文件某个区域的修改在使用MapMode.PRIVATE模式的缓冲区中都能反映出来,除非该缓冲区已经修改了文件上的同一个区域。内存和文件系统都被划分成了页。当在一个写时拷贝的缓冲区上调用 put()方法时,受影响的页会被拷贝,然后更改就会应用到该拷贝中。具体的页面大小取决于具体实现,不过通常都是和底层文件系统的页面大小时一样的。如果缓冲区还没对某个页做出修改,那么这个页就会反映被映射文件的相应位置上的内容。一旦某个页因为写操作而被拷贝,之后就将使用该拷贝页,并且不能被其他缓冲区或文件更新所修改
虚拟内存映射的概念见Java NIO 学习之背景知识
transferTo()和transferFrom()
在Channel与Channel之间传递数据而不需要通过Buffer。直接的通道传输不会更新与某个 FileChannel关联的position 值。请求的数据传输将从position参数指定的位置开始,传输的字节数不超过count参数的值。实际传输的字节数会由方法返回,可能少于请求的字节数。socket通道没有该方法,意味着不能用该API在socket通道之间传递数据,不过socket通道实现了WritableByteChannel和ReadableByteChannel接口,因此文件的内容可以用transferTo()方法传输给一个socket通道,或者也可以用transferFrom()方法将数据从一个socket通道直接读取到一个文件中。
FileLock相关API
channel()
返回创建这个文件锁的通道
release()
释放一个文件锁
建议在finally中调用
isValid()
测试一个锁是否有效。一个锁在release()方法被调用或它所关联的通道被关闭或Java虚拟机关闭时会失效
isShared()
测试一个锁是共享的还是独占的
如果底层的操作系统或文件系统不支持共享锁,那么该方法将总是返回false值,即使申请锁时传递的参数值是true
Socket通道独有API
open()
打开一个socket通道
open(SocketAddress remote)
等价于先open(),再connect到remote地址
socket()
返回此socket通道的对等socket
|
|
accept()
返回一个SocketChannel对象,如果处于非阻塞模式,当没有连接在等待时,立即返回null
|
|
configureBlocking(boolean block)
设置通道是否阻塞
isBlocking()
测试通道当前是否处于阻塞模式
只有面向流的通道才可以设置非阻塞模式,例如socket通道,Pipe里面的通道
blockingLock()
该方法会返回一个非透明的对象引用。只有拥有此对象的锁的线程才能更改通道的阻塞模式。可以确保在执行代码的关键部分时socket通道的阻塞模式不会改变以及在不影响其他线程的前提下暂时改变阻塞模式
|
|
connect(SocketAddress remote)
作用与socket的connect(SocketAddress endpoint)相同
SocketChannel与DatagramChannel都有connect方法,对于DatagramChannel来说,将其置于已连接的状态可以使除了它所“连接”到的地址之外的任何其他源地址的数据报被忽略。这是很有帮助的,因为不想要的包都已经被网络层丢弃了,从而避免了使用代码来接收、检查然后丢弃包的麻烦。当DatagramChannel已连接时,使用同样的令牌,你不可以发送包到除了指定给connect()方法的目的地址以外的任何其他地址,否则会导致
SecurityException异常当一个DatagramChannel处于已连接状态时,发送数据将不用提供目的地址而且接收时的源地址也是已知的。这意味着 DatagramChannel 已连接时可以使用常规的read( )和write( )方法,包括scatter/gather 形式的读写来组合或分拆包的数据
isConnected()
测试是否已经完成连接(与finishConnect()的区别???)
The connect( ) and finishConnect( ) methods are mutually synchronized, and any read or write calls will block while one of these operations is in progress, even in nonblocking mode. Test the connection state with isConnected( ) if there’s any doubt or if you can’t afford to let a read or write block on a channel in this circumstance connect( )和 finishConnect( )
不明白这段话的含义。。。不过好像间接说明了isConnected()与finishConnect()的区别
isConnectPending()
测试是否处于连接等待阶段
finishConnect()
测试是否已经完成连接
|
|
下面的示意图解释了连接建立的阶段以及finishConnect()方法调用的结果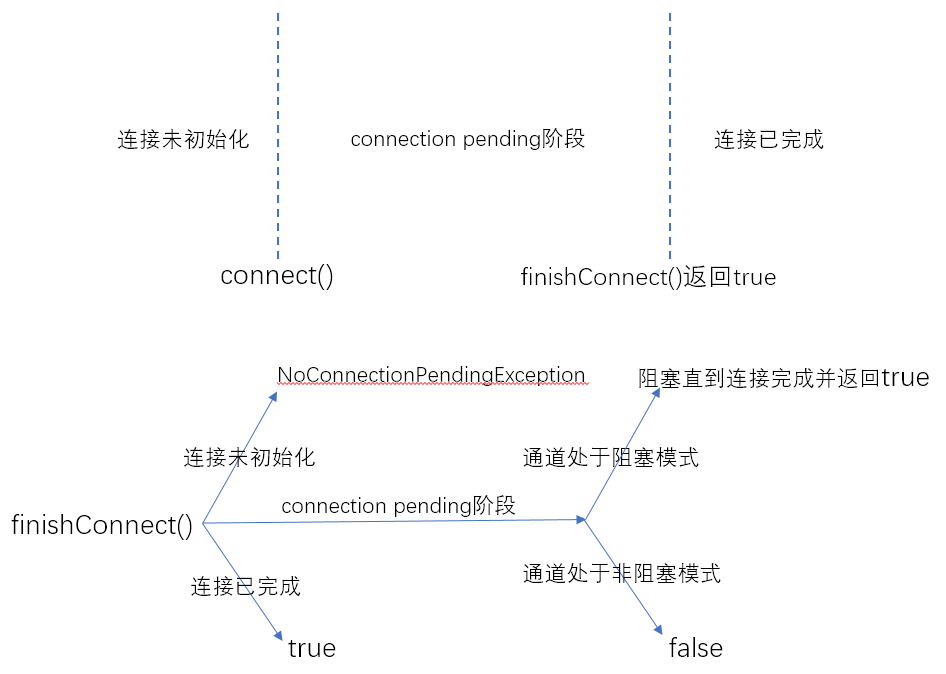
send(ByteBuffer src, SocketAddress target)
发送给定 ByteBuffer 对象的内容到给定SocketAddress对象所描述的目的地址和端口,内容范围为从当前position开始到limit处结束。如果DatagramChannel对象处于阻塞模式,调用线程可能会休眠直到数据报被加入传输队列。如果通道是非阻塞的,返回值要么是字节缓冲区的字节数,要么是“0”。发送数据报是一个全有或全无(all-or-nothing)的行为。如果传输队列没有足够空间来承载整个数据报,那么什么内容都不会被发送
receive(ByteBuffer dst)
将传入的数据报的数据复制到ByteBuffer中并返回一个SocketAddress对象以指出数据来源。如果通道处于阻塞模式,receive()会阻塞直到有包到达。如果是非阻塞模式,当没有可接收的包时则会返回null。假如提供的ByteBuffer没有足够的剩余空间来存放正在接收的数据包,没有被填充的字节都会被悄悄地丢弃
disconnect()
断开对等的socket的连接
不同于SocketChannel(必须连接了才有用并且只能连接一次),DatagramChannel对象可以任意次数地进行连接或断开连接。每次连接都可以到一个不同的远程地址
Pipe类API
open()
创建一个Pipe实例
source()
返回对应的source通道
sink()
返回对应的sink通道
Channels类API
newChannel(InputStream in)
返回一个将从给定的输入流读取数据的通道
newChannel(OutputStream out)
返回一个将向给定的输出流写入数据的通道
Channels类的方法常见用于包装标准输入输出流,即System.in和System.out