概述
Buffer是一个数据的缓冲区,与Channel联系紧密,Channel是IO传输数据的入口与出口,而Buffer是这些传输数据的缓冲区。示意图如下(箭头表示数据流方向):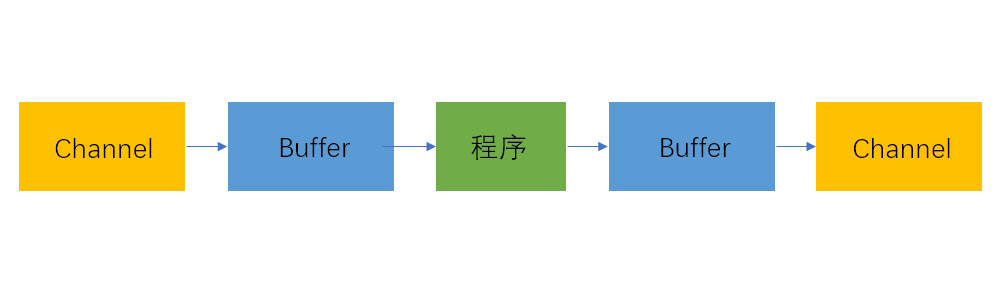
每个基本类型(除了布尔值)都对应着一种Buffer,如ByteBuff,LongBuffer等,最常用的是ByteBuffer。
buffer对象不是线程安全的,如果要在多线程环境中存取buffer,要做好同步工作
概念与原理
Buffer的属性
Capacity:Buffer能够容纳元素的最大数量。在Buffer创建时指定,不可改变。
Limit:对Buffer执行读或写操作的上界。等于Buffer中第一个不能被读或写的元素的索引
Position:下一个要被读或写的元素的索引
Mark:用于备忘的位置
这四个属性的关系总满足:0<=mark<=position<=limit<=capacity
一个新建的Channel的属性如图所示: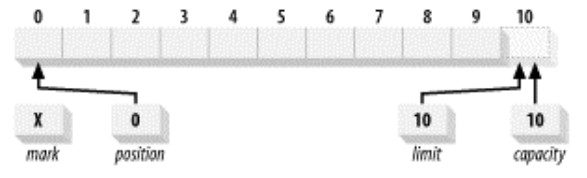
更多对于这几个属性的示意图见API详解
字节顺序
多字节数值被存储在内存中的方式一般被称为 endian-ness(字节顺序)。如果数字数
值的最高字节——big end(大端),位于低位地址,那么系统就是大端字节顺序(如图 2-
14 所示)。如果最低字节最先保存在内存中,那么小端字节顺序(如图 2-15 所示)。
大端: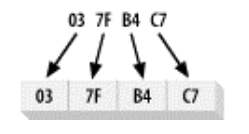
小端: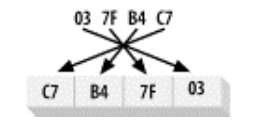
在NIO中,ByteOrder类封装了字节顺序,关于字节顺序的详细解释,可以参考Java NIO 探究ByteOrder
IP协议规定使用大端的网络字节顺序
直接缓冲区
在Java中,数组是对象,而数据存储在对象中的方式在不同的JVM实现中都各有不同,字节数组可能不会在内存中连续存储,或者垃圾回收机制可能随时对其进行移动,因此引入了直接缓冲区的概念。直接缓冲区通过使用固有代码来告知操作系统直接释放或填充内存区域,因此绕过了标准JVM堆栈,不受垃圾回收机制的影响。直接缓冲区的效率较高,创建和销毁的代价也比较高,因此使用直接缓冲区还是非直接缓冲区的性能权衡会因JVM,操作系统,以及代码设计而产生巨大差异
视图缓冲区
视图缓冲区的基本特点:与原始缓冲区共享数据元素,但每个缓冲区拥有各自的position,limit和capacity。视图缓冲区与原始缓冲区共用同一个备份数据的数组,对一个缓冲区内的数据元素所做的改变会反映在另外一个缓冲区上。如果原始缓冲区为只读,或者为直接缓冲区,新的缓冲区将继承这些属性,并且,字节顺序也与原始缓冲区相同。
另外,ByteBuffer允许创建视图来将ByteBuffer的数据映射为其他基本数据类型。ByteBuffer的position到limit索引处的元素都将成为视图缓冲区的内容,而其他部分(如limit后面的元素)对视图缓冲区是不可见的。视图缓冲区的元素个数等于ByteBuffer映射过来的元素个数除以该视图缓冲区的一个元素的字节数(例如CharBuffer一个元素有两个字节)
下面是一个ByteBuffer映射为CharBuffer的示意图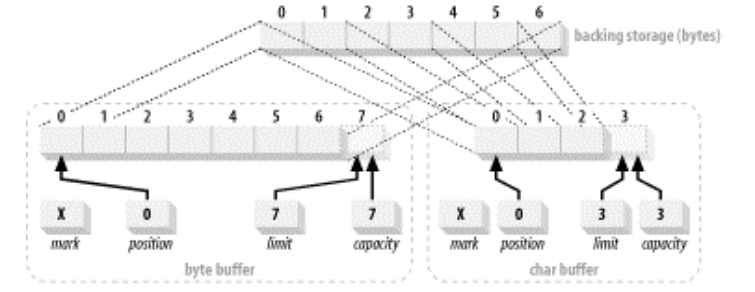
如图所示,CharBuffer视图与ByteBuffer共用同一个备份数组
与视图缓冲区相关的API有duplicate(),slice(),asReadOnlyBuffer(),asCharBuffer(),asLongBuffer()等
内存映射缓冲区
映射缓冲区是带有存储在文件,通过内存映射来存取数据元素的字节缓冲区。映射缓冲区
MappedByteBuffer通常是直接存取内存的,只能通过FileChannel类创建。映射缓冲区的用法和直接缓冲区类似,但是MappedByteBuffer对象可以处理独立于文件存取形式的的许多特定字符。出于这个原因,关于MappedByteBuffer的详细讨论留到讨论Channel的文章中
API详解
isReadOnly()
用于判断该Buffer是否只读。所有Buffer都可读,但并非所有都可写
get()
获取当前position索引处的元素,调用后position加一
get(int index)
获取index索引处的元素,调用后不影响position值
put(byte b)
在当前position索引处放入元素,调用后position加一
put(int index, byte b)
在index索引处放入元素,调用后不影响position
put()函数的元素类型因不同Buffer而异,这里以ByteBuffer为例
下面是put(byte b)操作对Buffer的影响示意图:
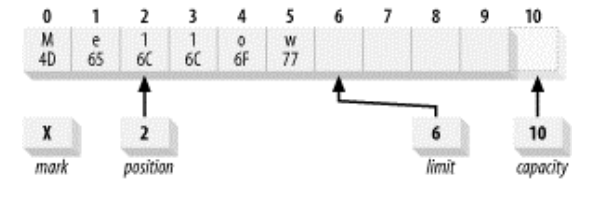
执行代码buffer.put((byte)'H').put((byte)'e').put((byte)'l').put((byte)'l').put((byte)'o');后,一个新建的buffer的状态如下图;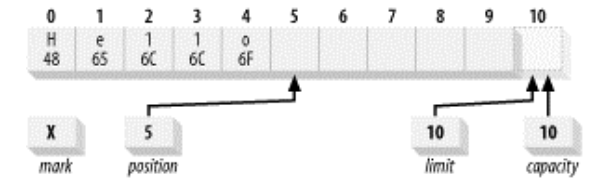
然后执行代码buffer.put(0, (byte)'M').put((byte)'w');后的状态: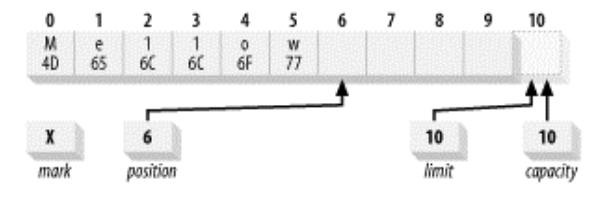
flip()
将buffer由写入状态“翻转”(flip)为读取就绪的状态
实质上是将limit设置为当前position的值,然后将position设置为0
例如上一个图中的buffer执行flip()后,状态如下: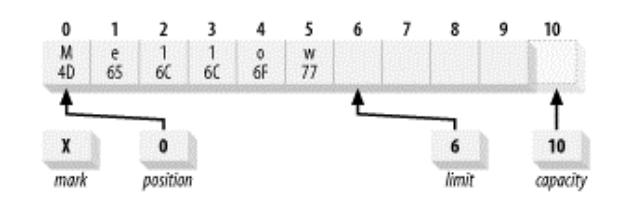
rewind()
已经读取过的buffer需要重读时执行的操作
实质上是不改变limit,而将position设置为0
clear()
将buffer中所有元素“清除”,使buffer转到写入就绪的状态
实质上是将limit设置为当前capacity的值,然后将position设置为0,因此,buffer中元素并未被真正清除
compact()
将buffer中已经读取的元素“清除”,保留未读取的元素
实质上执行了以下几步:
1.将未读取的元素复制到buffer的最前端,即将position到limit的元素复制到从0索引开始的位置
2.将position设置为(limit-position)的值
3.将limit设置为capacity的值
下面的示意图展示了buffer在compact()前后的状态:
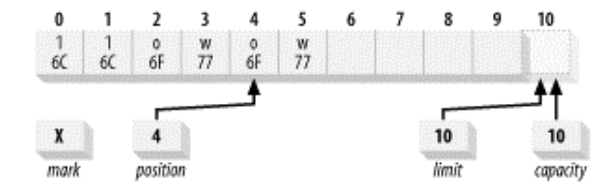
mark()
标记当前位置,即将mark设置为当前position值
rewind(),clear(),flip()操作会清除当前的mark值,limit(int limit)和position(int position)如果传入比当前mark值小的值,也会导致当前mark值被清除
reset()
跳转到上一次标记的位置,即将position设置为当前mark值
limit(int limit)
设置limit值
position(int position)
设置position值
equals()
对于buffer来说,equals返回true的充要条件是:
1.两个对象类型相同
2.两个对象剩余同样数量的元素
3.在每个buffer中应被get()返回的剩余元素的序列要一致
下面的一个示意图展示了一对“相等”的buffer: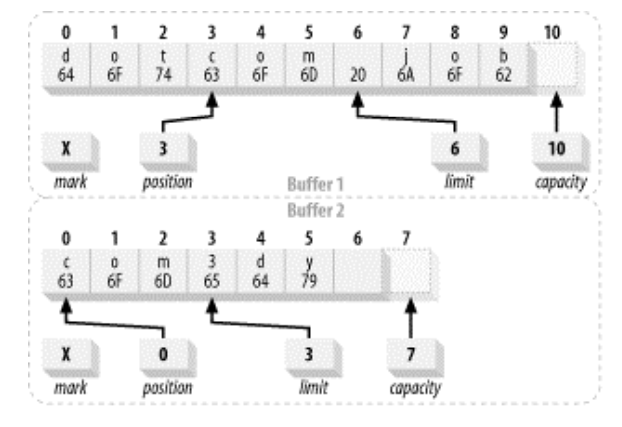
get(char[] dst, int offset, int length)
将buffer的数据释放到dst数组的[offset,length]的子数组中
get(char[] dst)
相当于get(dst, 0, dst.length()),因此需要注意的是,调用该方法意味着你要求整个数组被填充,如果buffer中的数据不够,你将得到一个异常
将一个buffer的数据释放到一个更大的数组中可以使用如下代码:
如果用来容纳数据的数组比buffer要小,或者不明确两者大小关系,可以用如下代码将buffer数据读取并处理:
put(char[] src, int offset, int length)与put(char[] src)
与上面两个get()的工作方式相同,但移动数据的方向相反,将src数组的数据复制到buffer中,同理,buffer.put(myArray)等价于buffer.put(myArray, 0, myArray.length),而如果此时buffer没有足够空间容纳myArray的全部数据,你将会得到一个异常
put(CharBuffer src)
将buffer的数据转移到另一个buffer中,当然前提是buffer有足够的空间容纳来自src的所有数据,如果容纳不下,你也会得到一个异常
allocate(int capacity)
静态方法,用于创建buffer,capacity指定了buffer的值
allocateDirect(int capacity)
同上,但创建的是直接缓冲区
isDirect()
判断该buffer是否为直接缓冲区
wrap(char [] array)
静态方法,用于创建buffer,新建的buffer将会用传入的array作为备份存储器,capacity等于array的长度
wrap(char [] array, int offset, int length)
作用同上,区别在于创建后position被设置为offset,limit被设置为offset+length
这个wrap函数创建的buffer仍然使用了整个array,另外两个参数只是用于设置buffer的初始值
wrap(CharSequence csq)
作用与上面两个wrap类似,用来包装一个CharSequence(例如String)
wrap(CharSequence csq, int start, int end)
作用同上,区别在于创建后position被设置为start,limit被设置为end
以上几个批量转移数据的方法以及创建buffer的方法是以CharBuffer为例的,除了最后两个wrap方法是CharBuffer独有的,其他的方法在另外的Buffer中有相同方法名、不同参数类型的实现
duplicate()
创建一个与原始缓冲区属性相同的视图缓冲区。
asReadOnlyBuffer()
作用与duplicate()相同,但返回的视图是只读的。只读是对于返回的视图缓冲区而言的,其内容是有可能改变的,因为在原来的buffer上做的修改会反映在只读的缓冲区上
slice()
作用与duplicate()类似,但slice()创建一个从原始缓冲区的当前位置开始的新缓冲
区,并且其capacity是原始缓冲区的剩余元素数量(limit-position)
asCharBuffer(), asShortBuffer(), asIntBuffer(), asLongBuffer(), asFloatBuffer(), asDoubleBuffer()
创建视图缓冲区来将ByteBuffer的数据映射为其他基本数据类型
创建映射为其他基本类型视图的API是ByteBufffer独有的
其他API
理解了视图和字节顺序后,ByteBuffer中还有些API功能类似且容易理解,不过多解释,罗列如下