本文是阅读《Database Systems Design, Implementation, & Management》12 ed 第13章做的笔记,有些是翻译,有些是原文。另外在这里极力推荐博文http://www.cnblogs.com/muchen/p/5318808.html, 对上卷/下钻和分片、分块等概念解释的非常清楚。
商业智能(BI)
BI指的是指用于获取、收集、存储和分析数据的一套的工具和过程,用于生成和展示能支持商业决策的数据。BI本身不是一个成品,而是由相关的概念、实践、工具以及技术组成的框架,总的来说,BI提供的框架用于这些方面:
- 收集和存储操作型数据
- 把操作型数据聚合成决策支持型数据
- 分析决策支持型数据而产生有价值的信息
- 给终端用户展现这些信息来支持决策
- 决策反过来会产生更多信息用于收集、存储等等(重新开始处理)
- 监测结果以评估决策的效果,这也将提供更多数据用于收集、存储等等
- 高精度地预测未来的行为和结果
实际上,收集和存储操作型数据是操作型数据库或系统负责的事,不过,BI系统会将这些数据作为输入以产生信息和知识。
商业智能的整体架构
下图13.1展示了BI框架的几个部分以及它们是如何联系起来的: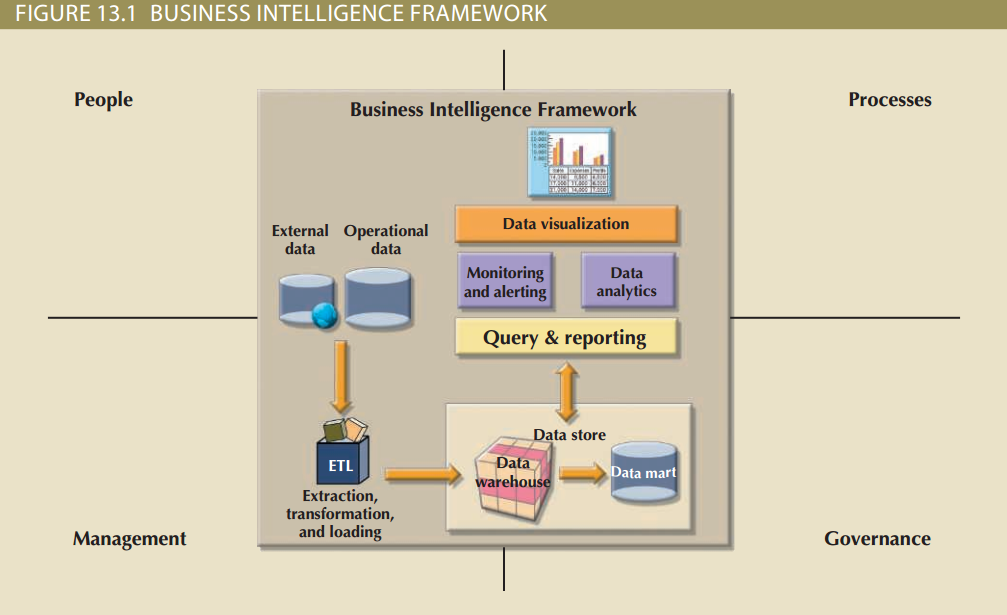
13.1图中展示了大多数现代BI系统的6个基本组件,下表13.2简要介绍了每个组件:
| 组件 | 描述 |
|---|---|
| ETL工具 | 数据提取、转化和装载(ETL)工具用于收集、过滤、集成和聚合来自内部或外部的数据。内部数据是由公司每天的业务操作产生的,例如产品销售记录、发票清单、交易信息等。外部数据源提供与业务有关但不在公司内部的数据,例如股票价格、市场指标、营销信息(如人口特征)和来自竞争对手的数据 |
| 数据存储 | 通常是一个数据仓库(data warehouse)或数据集市(data mark)。数据以结构化的形式存储以利于数据分析以及提高查询速度 |
| 查询与报表 | 该组件负责数据选择与检索,一般被数据分析师用于创建查询任务来访问数据库和产生报表。根据实现的不同,查询与报表工具会访问数据存储(更常见)即数据仓库/集市或操作型数据库 |
| 数据可视化 | 这个组件通过多种有意义且创新的方式将数据展现出来,以帮助使用者选择最合适的展现形式,例如汇总性的报表、地图、饼状图或条形图、静态或交互性的控制面板 |
| 数据监测与警报 | 该组件能对商业活动实时监测。BI系统可以精确地观测衡量业务系统性能和活动的标准,例如过去4小时下的订单、用户每个月对产品的反馈、所有地区的收入等。警报可以在达到给定的衡量标准(高于或低于某一基准线)时触发,然后系统会执行既定的任务,例如发邮件给经理或启动某程序 |
| 数据分析 | 该组件从数据存储中获取数据用于数据分析与数据挖掘。对数据的分析挖掘分为解释型的和预测型的,解释型分析从现有数据中发现它们的关系与类别,而解释型分析对数据建立静态模型,用于预测将来的值与事件,下一篇博文《大数据分析与NoSQL》会对此介绍更多细节 |
传统的信息系统聚焦于操作的自动化与报表生成,而BI系统聚焦于对信息的策略性与战略性的使用。为此,BI系统不仅需要技术,还需要融合先进的管理经验。在这方面最新的进展就是MDM的使用。MDM( Master data management)是为了在整个公司内实现对数据元素的合适识别、定义和管理的而衍生的一系列概念、技术与过程的集合。MDM的主要目标是在整个公司内提供对所有数据的综合而一致的定义。MDM保证公司中所有与数据打交道的资源(人、流程、IT系统等)对公司的数据都有统一且一致的视图。
商业智能的发展
通过表13.4,可以看到商业智能从传统主机的环境到桌面再到更现代化的基于云的、移动端的BI环境。现代BI系统的前身是第一代决策支持系统。决策支持系统(DSS)就是一套用来辅助管理决策的计算机工具。典型的DSS对比BI系统有更窄的关注点与使用范围。一开始,DSS只提供给公司中选定的管理者使用,然而随着桌面电脑的引入,DSS迁移到更灵活的平台,例如中型计算机,高端服务器,商业的服务器、应用和基于云的产品。这些发展极大地改变了DSS的使用范围;BI不再只提供给少数顶级管理人员使用,相反,如今BI系统对于整个公司的所有使用者,从生产线经理到一线员工再到移动代理商,都是可用的。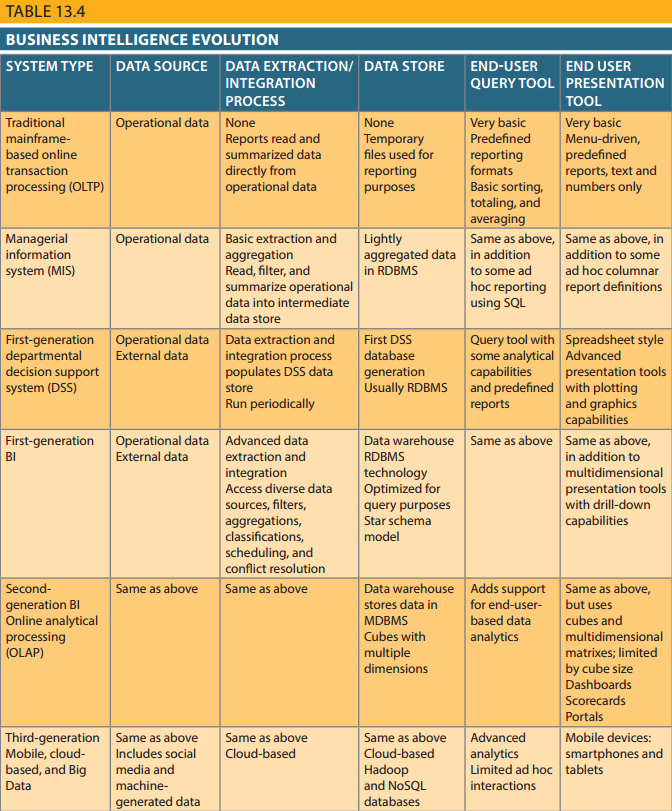
商业智能技术的发展趋势
- 数据存储的进步。SSD与SATA硬盘等技术的发展会提供更好的性能、更大的容量而使存储变得更快而且更加便宜。
- BI软件的蓬勃发展。
- 以服务的形式提供的BI。
- 大数据分析。
- 个性化的分析。
决策支持型数据
操作型数据与决策支持型数据的区别
略,见原书P602-P605
决策支持型数据库的要求
决策支持型数据的存储对数据库的多个方面(如数据库模式、数据提取与过滤和数据库容量等方面),提出了新的要求。就数据库容量而言,决策支持型数据库需要支持VLDBs(very large databases),相应的,还要支持高级的存储技术以及多处理器架构,例如SMP(symmetric multiprocessor)或者MPP(massively parallel processor)。其他方面的细节见原书P605-P606
数据仓库
Bill Inmon, the acknowledged “father” of the data warehouse, defines the term as“an integrated, subject-oriented, time-variant, nonvolatile collection of data that provides support for decision making.”In summary, the data warehouse is a read-only database optimized for data analysis and query processing. Typically, data is extracted from various sources and are then transformed and integrated—in other words, passed through a data filter—before being loaded into the data warehouse. As mentioned, this process is known as ETL.
数据集市(Data Marts)
A data mart is a small, single-subject data warehouse subset that provides decision support to a small group of people. In addition, a data mart could be created from data extracted from a larger data warehouse for the specifc purpose of supporting faster data access to a target group or function. Tat is, data marts and data warehouses can coexist within a business intelligence environment. The only difference between a data mart and a data warehouse is the size and scope of the problem being solved.
星型模式(Star Schemas)
星型模式是将多维的决策支持型数据映射到关系型数据库中的一种数据模型。星型模式表现数据的形式是:一个位于中心的称为事实表(fact table)的表格,与一个或多个称为维度表(dimension table)的表格以1:M的关系连接。基本的星型模式由四个部分组成:事实,维度,属性与属性层次。
事实(Facts)
“事实”是代表了特定的业务方面或活动的衡量值。例如,销售额是代表产品和服务销售的衡量值。在商业数据分析中,事实常常指的是部门、花费、价格、收入等。事实一般被存储在位于星型模式的中心的事实表中。事实表(fact table )里面存储着事实,而事实又链接到它们的维度(dimension)。事实有时是通过在运行时计算或导出的,这些事实又被叫做指标(metrics),以将其与直接存储的事实区别开来。我们可以每隔一段时间用操作型数据库的数据更新一下事实表。
维度(Dimensions)
维度是给特定的事实提供更多视角的修饰性特征。回想一下之前的内容可以发现维度是非常有趣的,因为决策支持型数据几乎总是与有关联的数据被一起查看。例如,销售额可以通过不同地区、不同时间间隔来比较。典型地,BI系统常常可以处理这样的问题——“比较一下产品X在不同地区、从2006年到2016年每年第一季度的销售额”。在这个例子中,销售额有产品、地点和时间三个维度。实际上,维度就相当于一个放大镜,你可以通过它来研究事实。维度一般存储在维度表中。图13.6显示了一个销售额的星型模式,其中,销售额有产品、地点和时间维度。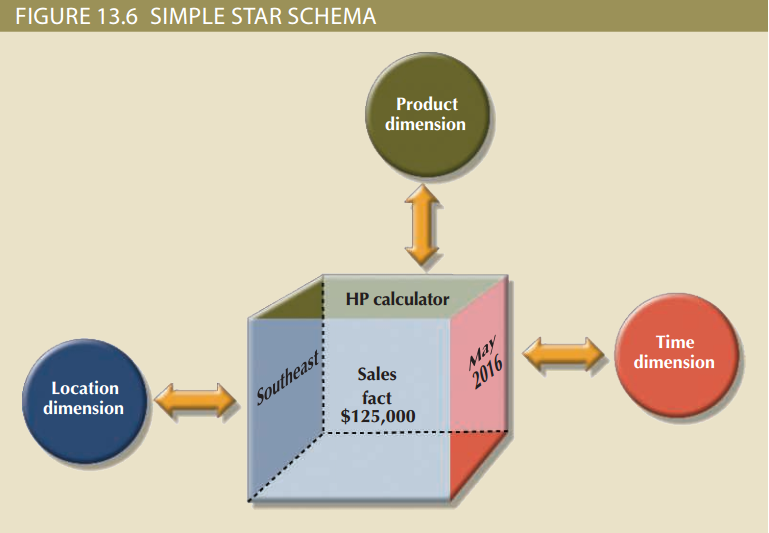
属性(Attributes)
每个维度表都含有很多属性,属性常被用来对事实进行查找、过滤和分类。维度通过它们的属性给事实提供了描述性的特征。因此,数据仓库设计者必须定义常见的业务属性,它们可以被数据分析师用来缩小查找范围,给信息分组或描述维度。还以销售额为例,表13.10解释了它每个维度可能具有的属性。
可以看出,星型模式通过事实表和维度表给数据分析师提供了符合格式的数据。而且,额外而没必要的数据不会再给分析带来负担(例如订单号和状态这些通常在操作型数据库中的数据)。
概念上来说,用一个三维的立方体来描述销售额的多维数据模型是最好的。当然这并不意味着你给事实表添加的维度数量有限制,在这里用三维模型只是为了更容易将问题可视化。图13.7展现了具有产品、地点和时间维度的销售额。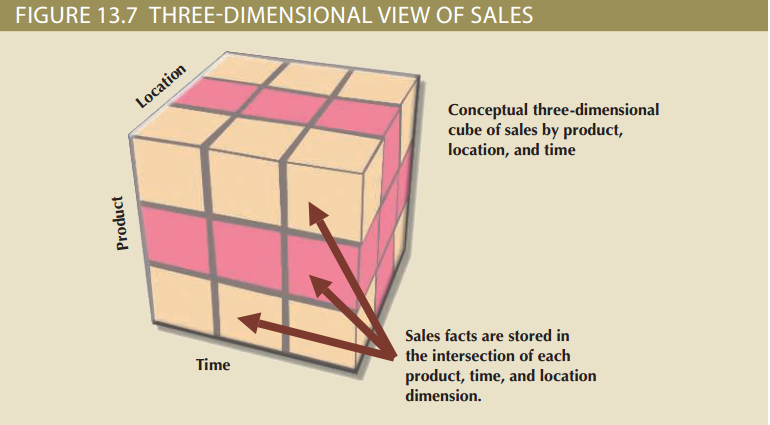
要记住这个立方体只是多维数据的一个概念上的表示,并不意味着数据以这样的物理结构存储在数据仓库中。
多维数据分析的一个主要特征就是它可以聚焦于立方体的某一“片(slide)”,例如,可能产品经理想查看某一产品的销售额,而商场经理想查看某一商场的销售额。用多维分析的术语来说,这种聚焦于立方体的某些片而进行更加详细的分析的能力,称为切片和切块(slice and dice)。图13.8解释了切片和切块的概念。注意,通过立方体的一次切割就产生一个“切片”,切片与切片相交产生了一些小的立方体,就是“切块”。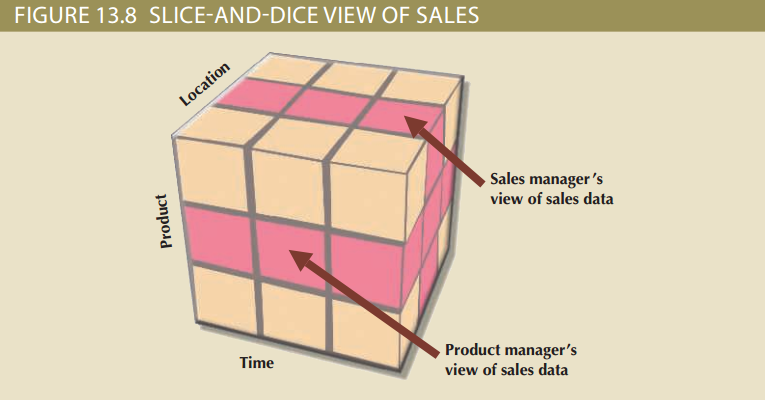
属性层次
维度的属性可以按照一定的属性层次来排序,属性层次提供了数据的自上而下的数据组织形式,主要用于两种数据分析:聚合以及下钻/上卷。例如图13.9展示了地点维度是怎样通过地区、州、城市和商场来组织成一个属性层次的。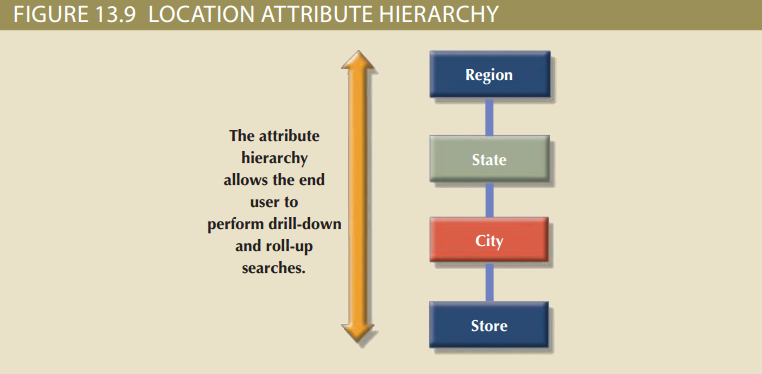
星型模式表示
事实表与每个维度表以多对一(M:1)的形式相联系,也就是说,事实表中的多个行对应每个维度表的一行。事实表和维度表是通过外键约束联系的。图13.11展示了事实表与维度表在数据库中的关系与表示。为了展示星型模式非常易于拓展,图中除了之前说的三个维度,还加了顾客维度——而这只需在销售事实表中添加CUST_ID,并在数据库中添加一个CUSTOMER表即可。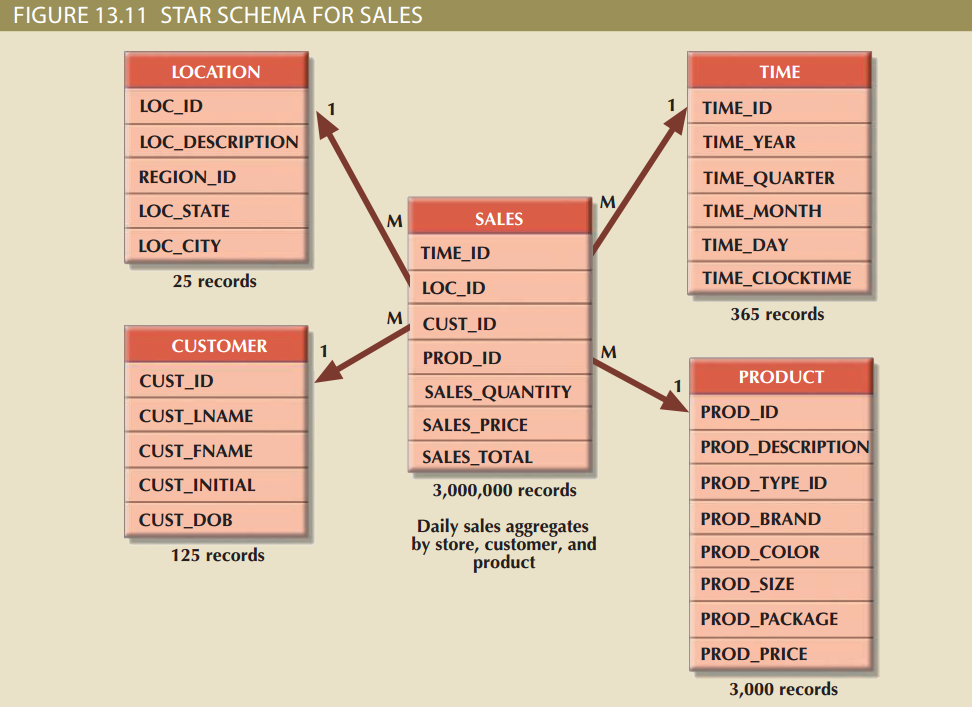
事实表的主键是一个复合主键,组成这个复合主键的每个字段都以外键约束的形式与一个维度表产生联系,也就是说这些字段是维度表中的主键,例如图中事实表的主键是由TIME_ID, LOC_ID, CUST_ID, 和 PROD_ID组成的。
针对星型模式的性能优化技术

有一些看不懂,挖坑待填
联机分析处理(OLAP)
BI系统支持OLAP是由于具有下面三个特点:
- 多维数据分析技术
- 高级数据库支持
- 易于使用的终端用户接口
注:这部分有很多内容,暂时不想学,先放一下