第二章
各个包的约定导入写法
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
import statsmodels as sm
Magic命令
pwd:显示当前路径
%run:用于运行py脚本,如果希望脚本能够使用当前命名空间中的变量等,可以使用%run -i
%load:以文本形式导入指定文件的内容,例如导入py文本,txt文本等
%magic:查看所有magic命令的用法
%hist:打印输入命令的历史
%debug:在最新的异常跟踪的底部进入交互式调试器
%pdb:遇到任何异常自动进入调试器
%reset:删除所有在交互式的命名空间内定义的变量/名字
%page OBJECT:通过分页器打印输出某对象
%time statement :计算单条语句的运行时间
%timeit statement:多次运行该语句并计算平均运行时间,适合运行时间很短的语句
%who:显示在交互式命名空间中定义的变量,如果传入参数,比如str,将会列出指定类型的所有变量
%whos:同上,但显示更加详细的信息
%xdel variable:删除某一变量并尝试清除IPython构件对该变量的引用
%matplotlib:将matplotlib集成到IPython或Jupyter notebook。注意在Jupyter notebook中改为使用%matplotlib inline
下列目前只能在IPython中使用,Jupyter notebook无法使用
%paste:执行剪切板中内容。
%cpaste:进入粘贴状态,可以任意粘贴剪切板中内容与编辑,输入--并回车以执行,或按ctrl+C退出而取消执行。
另外,Tab键可以智能提示;变量或函数后加问号?可以查看信息,还可以结合通配符*来查找变量和函数;方法名后加??可以显示其源码;用前缀!可以执行shell/cmd命令
random模块
符合标准正态分布的元素生成:np.random.randn(m, n) #生成m行n列的二维数组
其他相关函数用法见 http://blog.csdn.net/m0_38061927/article/details/75335069
多维数组ndarray
ndarray对象属性
1、ndim表示维度
2、shape属性表示形状
二维数组的shape为有两个元素的tuple,一维数组的shape为只有一个元素的tuple(不过要加个逗号区别于整数外加括号)
3、dtype表示数据类型
创建数组
1、np.array(object)
得到一个一维数组,object为序列等对象
|
|
2、np.arange()
相当于使用python的range()创建list后再转为ndarray类型的一维数组
3、np.ones()
|
|
例子:
np.ones(n):创建一个一维数组,其中具有n个float64类型的1
np.ones((m,n)):创建一个m行n列的二维数组,其中具有n个float64类型的1
4、np.zeros()
参数含义同上
np.zeros(n):创建一个一维数组,其中具有n个float64类型的0
np.zeros((m,n)):创建一个m行n列的二维数组,其中具有n个float64类型的0
5、np.empty()
参数含义同上
|
|
6、np.full()
|
|
说白了就是使用指定shape和指定的值初始化ndarray
ones(), zeros(), empty(), full()这几个方法都有对应的xxx_like()方法,功能类似,但增加一个ndarray类型的参数,使用其shape和dtype
7、np.eye()与np.identity()
np.eye(n)为创建n行n列的单位矩阵,其对角线元素为1,其余位置为0
数据类型与形状
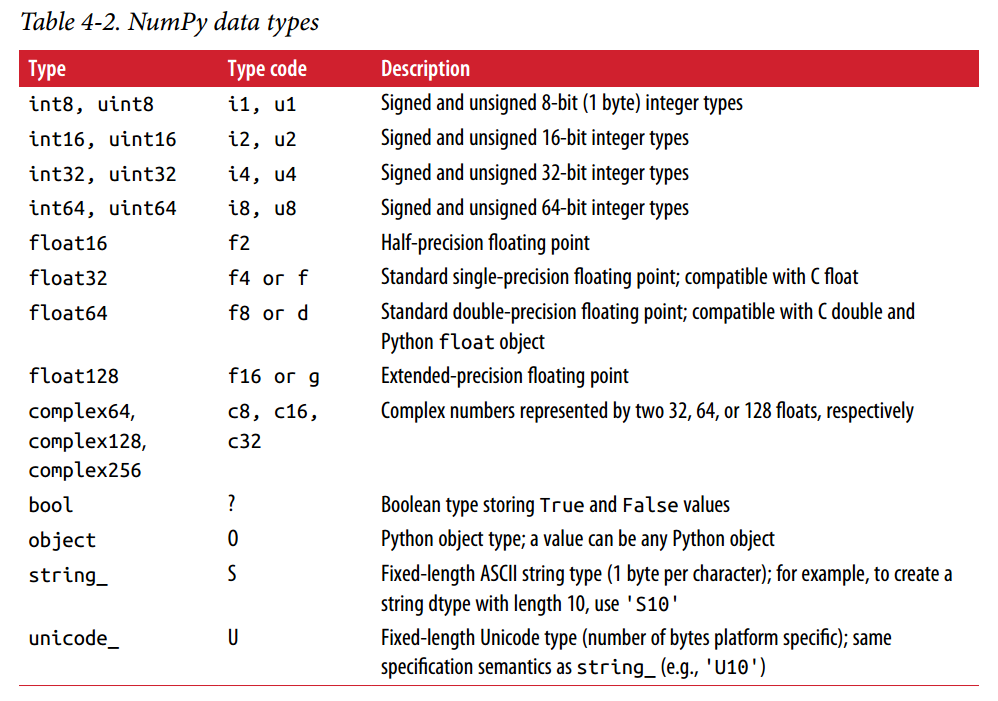
1、成员方法arr.astype()
得到更改了dtype的arr,参数可以是dtype或者ndarray,即直接指定类型或使用其他数组的类型
注意其返回一个新的ndarray
dtype参数传入时可以使用简称,例如(dtype=’u4’)表示dtype为unit32
要十分注意numpy.string_类型,这种类型的长度是固定的,所以可能会直接截取部分输入而不给警告。
2、成员方法arr.reshape()
得到更改了shape的arr,参数是tuple,注意这个方法也返回一个新的ndarray
Broadcasting
Broadcasting就是在数组的运算遇到数组shape不匹配时,numpy自动转换数组形状然后运算。这个特点可以使得一些操作变得很简便,而不用编写复杂低效的循环。
下面是三个例子:
下面是这三个例子的图解:(来自 PythonDataScienceHandbook)

broadcasting的三个规则:
Rule 1: If the two arrays differ in their number of dimensions, the shape of the one with fewer dimensions is padded with ones on its leading (left) side.
Rule 2: If the shape of the two arrays does not match in any dimension, the array with shape equal to 1 in that dimension is stretched to match the other shape.
Rule 3: If in any dimension the sizes disagree and neither is equal to 1, an error is raised.
索引与切片
基本与python的序列索引与切片相同,但有一些重要的区别:
1、更简洁的索引
例如,可以使用arr[0, 2]代替arr[0][2],即用逗号分隔各个维度的索引值
2、切片为视图
array的切片后的结果只是一个views(视图),用来代表原有array对应的元素,而不是创建了一个新的array。但python中list的切片是产生了一个新的list。
因此,对切片的所有操作,都会反映在原始数组上
3、数组的切片实际上是对最外层的list切片
例如:
4、一些需要注意的使用
可以给定多个索引对切片再进行切片例如对于二维数组a,a[:2, 1:]或a[:2][1:]表示取前两行,第二列之后的部分
仅使用冒号:可以取出该索引对应维度的所有元素,例如对于a,a[:,:2]表示先选中a的所有行(第一个索引对应二维数组的”行”维度),再取每行的前两个元素,最后是一个n行2列的数组
5、切片赋值
例如arr为array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]),执行arr[5:8] = 12后,将得到array([ 0, 1, 2, 3, 4, 12, 12, 12, 8, 9]),并不会改变数组的元素个数,
因此,下面这种切片赋值无法使用:
6、成员方法copy()
如上一点所述,切片只是视图,如果想在内存中复制一份,可以使用copy()方法,例如arr[5:8].copy()
布尔索引
使用方法为data[bool_arr],用于取出该布尔数组True元素在data中对应位置的元素
看完书中例子,个人认为一般来说,bool_arr只需要一维的,因此只针对n维数组的最外层list操作
因此书中说“布尔数组和data数组的长度要一样”。其实就是说作为索引的布尔数组的元素个数必须与执行操作的数组最外层list的元素个数相同
例子:
有几点要注意:
1、用布尔索引取出的数组维度与原数组保持一致,这与用一般索引不同
例如上面例子将bool_arr改为[True,False,False,False],取出的将是array([[0, 1]]),要注意区别于用data[0]取出的array([0, 0]),它们维度不同,一般的索引会导致降维,布尔索引不会。
2、使用布尔索引取数组作为右值时,会返回新创建的数据,而作为左值时,是直接修改原数组
例如执行d=data[bool_arr]后,d与data不共享内存;data[data>0]=0会将data中大于0的元素全部赋值为0,而不是先复制一份然后在其上赋值。
3、布尔数组可以结合布尔运算符一起使用,但不能使用python中的not、or、and,而要用~、|、&
例如和~一起使用,~bool_arr可以得到对应元素相反的布尔数组
题外话:经过我的测试,其实bool_arr也可以不是一维的,但是那样用法就更加复杂了,也没必要在这里列例子和解释,个人觉得没必要理会这些(连书都没说,我自己发现的而已)。
花式索引
使用整数数组或整数list来作为索引。从书中例子看来,这个整数数组/整数list只需要用一维的,和布尔索引效果差不多,用于选取数组的最外层list的元素。下面是一些例子:
|
|
索引小结
(1)arr[][]...这种形式可以把中括号一个一个解读
(2)同一个中括号内的整数索引、布尔索引、花式索引会先broadcast,结果数组的形状由broadcast得到的数组决定。如果这几个部分无法broadcast(详见broadcast的规则),会报错。
(3)如果(2)中的几种索引与切片在同一中括号中使用,如果作用对象是二维数组,可以简单理解为“选中xx行/列”
(4)如果中括号中含有(2)中的几种索引之一,得到的结果就会是新的数据
数组转置和轴交换
转置也是返回一个view,而不是新建一个数组。有两种方式,一个是transpose方法,一个是T属性:
arr.T返回数组转置
arr.transpose(数字元组)用元组中的数字指定轴。例如arr.transpose((1, 0, 2))表示交换一个三维数组的0维和1维
arr.swapaxes(a, b)可以指定只交换哪两个轴
通用函数
universal function, 或 ufunc, 是用来在ndarray中实现element-wise操作的。
一元函数举例
np.sqrt(arr),求开方
np.exp(arr),求自然底数e的n次方,指数为数组中的元素
np.modf(arr),返回一个二元元组,分别为整数部分和小数部分。例如可以np.modf(arr1/arr2)
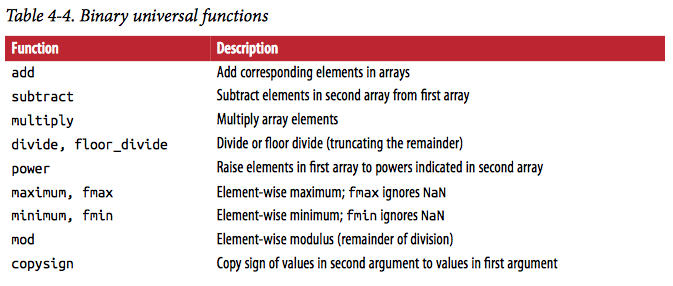
二元函数举例
np.add(arr1, arr2),数组加法
np.maximum(arr1, arr2),取arr1和arr2中相同位置的较大值
可选输出
一元或二元函数都有一个可选的参数out表示应该将结果输出的位置。例如,np.sqrt(arr,arr)会对arr求开方后放回原数组,即达到了计算后改变原数组数值的效果。
常用一元与二元函数


面向数组编程
meshgrid()
[X,Y] = meshgrid(x,y) 将向量x和y定义的区域转换成矩阵X和Y,其中矩阵X的行向量是向量x的简单复制,而矩阵Y的列向量是向量y的简单复制。
假设x是长度为m的向量,y是长度为n的向量,则最终生成的矩阵X和Y的维度都是 nm (注意不是mn)。
np.linspace()
|
|
详情可用np.linspace?查看
np.arange()
|
|
详情可用np.arange?查看
np.where()
numpy.where(cond, x, y)函数是一个向量版的三相表达式,x if condition else y。
cond为布尔数组,x和y为标量或数组。事实上这三个参数需要能够broadcast。如果cond中为true,取x中对应的值,否则就取y中的值。
where在数据分析中一个典型的用法是基于一个数组,产生一个新的数组值。假设我们有一个随机数字生成的矩阵,我们想要把所有的正数变为2,所有的负数变为-2。用where的话会非常简单:
|
|
数学和统计方法
一些能计算统计值的数学函数能基于整个数组,或者沿着一个axis(轴)。
可以使用aggregations聚合(常称为reductions降维),比如sum, mean, and std(标准差).例如arr.mean()对整个数组求平均值
mean, sum这样的函数能接受axis作为参数来计算统计数字,例如arr.mean(axis=1),沿着轴1(对于二维数组就是列轴,横的方向)进行聚合。
还可以用np.sum(arr)/np.mean(arr)等来调用
布尔数组的方法
布尔数组可以用上述的sum来统计True的个数。还有两个其他方法,any和all。any检测数组中只要有一个ture返回就是true,而all检测数组中都是true才会返回true。
arr.sort()
可以直接调用数组的sort方法,不过这会改变原有数组的顺序。如果使用np.sort()函数的话,会生成一个新的排序后的结果。
一个计算分位数的快捷方法是先给数组排序,然后选择某个排名的值:
|
|
通过文件读取或保存数组
np.save()和np.load()
例如,np.save('../examples/some_array', arr)。数组会以未压缩的原始二进制模式被保存,后缀为.npy。即使保存的时候没有加后缀,也会被自动加上。
可以用np.load来加载数组:arr = np.load('../examples/some_array.npy')
用np.savez能保存多个数组,保存为npz格式,加载npz文件会得到一个dict。
线性代数
矩阵乘法
在MATLAB里, 代表矩阵乘法。但是在numpy里,表示element-wise prodct。要想做到矩阵乘法,要用函数dot,x.dot(y)等同于np.dot(x, y)。
@符号也能实现矩阵乘法,即arr1 @ arr2。
np.linalg模块
np.linalg中的函数,可以完成转置、求秩、SVD、QR分解之类的事情


伪随机数的生成
比如我们可以用normal()得到一个4 x 4的,符合标准正态分布的数组:
samples = np.random.normal(size=(4, 4))
之所以称之为伪随机数,是因为随机数生成算法是根据seed来生成的。也就是说,只要seed设置一样,每次生成的随机数是相同的:
np.random.seed(1234)
当然,这个seed是全局的,如果想要避免全局状态,可以用numpy.random.RandomState来创建一个独立的生成器:
rng = np.random.RandomState(1234)
下面是一些random模块的函数:

pandas的数据结构
从此处开始,不再做记录型的笔记,只记录一些看后觉得觉得需要注意的地方
1.Series和DataFrame的index/columns是不可变的,但可以直接替换,例如se.index=[...]
2.直接替换Series和DataFrame的index相当于给行或列改名字,而reindex()相当于重排各行或各列。注意,不会修改原来的对象,而是得到新的Series或DataFrame
3.se.drop()与df.drop()用于删除数据,但并不会修改原对象中的数据,而是在复制后的对象上删除后返回;如果需要删除原数据,可以指定参数inplace=True
4.Series用中括号索引时,可以用单个label、label的list、label表示的切片,而且在label不是整数时,前面几种方法的label也可以改为使用整数代替。还可以使用布尔索引,因此可以用布尔表达式筛选所需数据,例如se[se < 2]
5.DataFrame的单个列可以用df.label取
6.DataFrame用中括号索引时,可以用单个label、label的list来索引列;可以用整数值表示的切片取行,也可以用一维布尔索引来取行,因此可以用布尔表达式构造SQL中的行选择,例如df[df['col0'] > 5](此处df[‘col0’]可用df.col0代替);还可以用多维布尔索引来选中符合条件的值,不符合的位置为NaN,由此可以实现整个表格的数据处理,例如df[df < 0] = 0可以将所有小于0的值替换为0。
7.df.loc[x,y]和df.iloc[x,y]语法中,x表示选择行,y表示选择列。Series也可以用loc和iloc,在label为整数时,这两个方法可以避免索引值歧义。
8.Series和DataFrame进行运算也遵从broadcast规则,但默认情况下是匹配列的,即Series的shape为(n,),在与(m, n)的DataFrame运算时,Series往行的方向(往下)拓展,拓展成(m, n)再运算;在使用算术相关方法例如add(), sub(), mul(), div()等时,可以指定axis参数的值为”index”来匹配行,而使Series拓展时往列的方向(往右)拓展,即Series的shape为(n, 1),与(n, m)的DataFrame运算时broadcast为(n, m)。这两种情况本质上是对Series的shape的理解不同
9.要理解几个概念,“行轴”是往下的,“列轴”是往右的,“在行上聚集”是指在行的方向上(即垂直方向)使用聚集函数,简单点说就是对每一列使用聚集函数;聚集函数df.mean()等有一个axis参数,就是用来指定在什么方向(哪个轴上)聚集的。而axis参数的作用可以推广到其它函数,例如DataFrame的apply(),传入一个函数并指定axis=’columns’时,效果是将该函数运用到每一行。